Can you explain how BEAST works using an example?
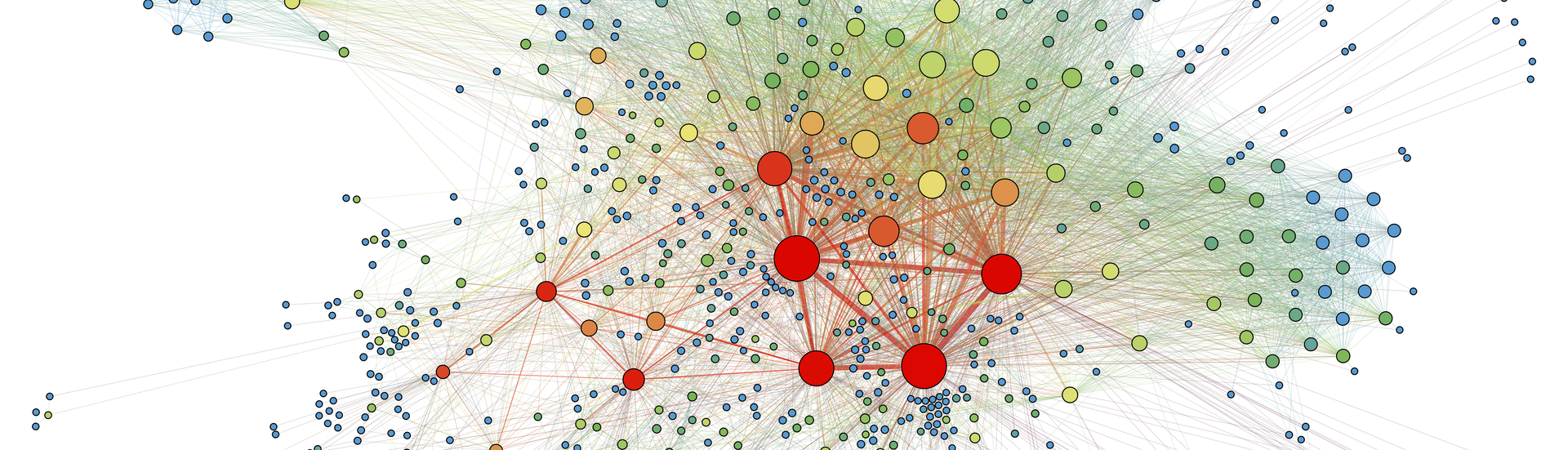
BEAST focuses on how processes behave. There is a host of graphs containing benign as well as harmful behaviour stored in the backend. Now, we can use our rules to ensure that we identify a malicious processes, because with every change in the graph we scan the environment of the node for known patterns. BEAST shows its strengths when malicious behaviour is distributed over multiple processes. BEAST recognises these connections by means of subgraph matching and compares the current behaviour with existing rules.
A malicious process typically involves the following sequence: Process 1 creates a file in a specific folder and launches process 2. This process in turn changes firewall rules and other security settings so that it can operate later without interruption - for example when stealing access credentials or credit card information. At the same time, process 1 downloads another file, launches process 3 and then deletes itself automatically to cover its tracks. Process 3 establishes the persistence of the malware and creates a RunKey with an entry in the registry on process 2. RunKeys use malware authors to create persistence so that, in the event of a restart, the malicious processes launch automatically as well. This is what the rule looks like: we have a directed graph with three process nodes and three file nodes. We also know the sequence of the individual processes. The scanner compares this behaviour with the existing graphs and can clearly classify it as malicious. This is because individual process steps are not in themselves malicious. One example is the downloading of files from the Internet. This happens not only with malware, but also with updates for programs that are installed on the computer.

We wanted to understand the detection better by having and being able to view the data. And since behavioural data in its natural form is actually graphic, it was obvious that we should use a graph database. This allows us to handle the data and the associated data growth very efficiently.
Why did you decide to use a graph database? What are the advantages of the technology compared to the former behaviour analysis?
We wanted to understand the detection better by having and being able to view the data. And since behavioural data in its natural form is actually graphic, it was obvious that we should use a graph database. This allows us to handle the data and the associated data growth very efficiently. It works simply and quickly. Processes can be represented as a tree, for example. A high level process launches multiple low level processes, which in turn each launch multiple lower level processes of their own. In this way, we have stored both the process structure and other information such as file accesses in a single system, so we can then understand the relationships. The processes then form the central nodes in the graph. Further information strands branch off from these, such as file accesses or modifications to the registry.
The graph visualises this behaviour really well and makes it very clear. It also allows the infection path of a malware strain to be traced very precisely. We also store the history of the process chain at the same time. This is a big advantage over to the former system, which had to make do with no history. With that, we only had the one scoring value that classified the file as good or bad. BEAST manages without any scoring at all. We match a current process with the graph database and check whether the behaviour is benign or malicious.
The graph database, and therefore the data as well, is always stored locally with the client, and we delete data after about a week to ensure good performance. The required storage space is a maximum of 200 MB. If BEAST detects an abnormality, it sends the data anonymously to our telemetry backend - provided the client has agreed to this data transfer. For instance, we can check whether a detection is a false positive and take steps to improve detection.
How did the selection of the graph database go? Which criteria were important? Why did you decide to use the graph database?
When we started the project in 2014, graph databases were still in their infancy. So we had to take a close look at what would fit our own very specific and very demanding requirements. The application would have to run directly in the client, using little memory and generating minimal resource load for the customer. We wanted a database that could be easily integrated into our own programs so that we had maximum control over how much memory and CPU the database needed. As such, we couldn’t use existing databases, as those were designed to run on high-performance server systems and therefore not suitable for most PCs. After an in-depth market survey, it was clear that none of the solutions available on the market at the time, such as the enterprise solution Neo4j, met our requirements. So we decided to build our own solution. We used SQLite, a relational database with tables that can be embedded in our own processes, as a role model. Graph databases basically work differently. Even today I still don’t know of any database that fulfils all of our requirements.
We wanted a database that could be easily integrated into our own programs so that we had maximum control over how much memory and CPU the database needed. As such, we couldn’t use existing databases, as those were designed to run on high-performance server systems.
How did the development process go? Did you have to develop a lot on your own or could you rely on suitable tools?
Of course, we had to do the basic work and develop a lot ourselves. As I personally had only limited experience with the topic, there was a pretty steep learning curve. Before we could even get started with the actual graph database, we started with event processing. This is the question of where the data for the graph comes from. Here we could rely on the existing data backend of Behaviour Blocker. We had to enhance it to meet our own performance requirements. In addition to the database, we also had to define the graph schema - i.e. flesh out definitions of what constitutes nodes and edges. And how the data is connected, so that I can subsequently search efficiently and without diversions.
One fascinating subject is scanning on the graph. Comparing two graphs with each other efficiently is actually mathematically difficult to solve. And last but not least, we needed graph-based algorithms for removal to identify the data to be deleted. We were able to use the standardised graph format GraphML to export graphs. Tools to visualise graphs, such as yEd, were also available at that time. Nevertheless, we also developed our own tools in which the graph could be visualised. In addition, we embedded the scanner directly into the visualisation. This way we can visually compare new signatures with the graph and, for example, see which subgraph is responsible for the malicious process.
Can you say what was the most interesting learning experience for you in the development phase?
I have actually learned something new every day over the past few years. As we were replacing an existing component, we eventually came to the conclusion that all the existing features needed to be carried over. Nothing should be different for the customer and BEAST should offer the same range of functions. Therefore, we had to deliver a fully featured version with all the functionality almost in one go, which is very unusual. In a normal development process, a technology grows over time and is successively enhanced - features and functions are added or improved bit by bit. As such, testing during development was very important. The writing of new rules was also interesting. If you think that “There is no benign program that would responds like this”, that on its own teaches you a lesson. You would be surprised to see how many perfectly benign and legitimate programs act a bit “shady” and therefore display a behaviour that looks very similar to malware.
Were there moments when you were truly surprised?
I was very surprised by the release - because it really went without any problems. At this point I would like to give credit to and thank the whole team and everyone who was involved in this big project. We can be really proud of what we achieved. The expectations were of course immense in the run-up, because we were replacing a technology that had proven itself in the field and that worked well. Releases of new components are usually always a bit bumpy and not without risk. After all, we can never test all the special circumstances that our customers eventually encounter. A few minor bugs did appear gradually, which we fixed quite quickly. All in all, we are relieved that everything went smoothly. It was an advantage that we did not roll out BEAST to all of our customers at the same time and only ever dealt with certain customer groups within small margins. This meant that we were always able to act quickly to make modifications in the event of problems.
Are there any plans for further development of BEAST?
The plan is to continue linking BEAST with existing and new technologies, as we have already done with DeepRay. This way everyone will benefit from the wealth of data in the graph database.
Specifically, we are working on improving the performance even further. At the same time, we want to open up new event sources so that we can enhance the graph and keep improving our rules. By event we mean one process launching another or a process creating a file. Then we can see more of what the malware does. We can’t observe every CPU instruction yet, but we can receive information from the system components at the action level. And the more information we have, the more accurately we can modify our rules. But we still have lots of ideas besides that, because BEAST offers great potential.



